
Abate2012dependency
Updated on 12/10/2022 🗒️ Edit on GitHubDependency Solving: a Separate Concernin Component Evolution Management
Note that this paper seems very similar to [1], although the date is one year earlier. I’m going to do a more superficial reading to look for new information. It would be interesting to have more context about why there are these two similar papers
TLDR
This paper [2] is indeed similar to [1] - the authors want to establish dependency solving as a “separate concern” by using CUDF and rationalize this by showing how well it works with implementations from the MISC competition. They show that complexity comes down to:
- conflicts (metadata or different versions of the same thing),
- large number of software packages in the repository, and
- complexity of user preferences given 1 and 2.
Overview
The paper has a nice introduction with “the law of continuing change”
A program that is used and that as an implementation of its specification reflectssome other reality, undergoes continual change or becomes progressively less useful.
And this seems similar to the upgrade problem from [1]. Basically, the more compoenents with different dependencies, the harder the problem, and the greater importance of tools to help. They note that “software modules” have different names depenending on the environment (e.g., some things have extensions, plugins, bundles, add-ons, etc.)
The Upgrade Problem
The authors again describe the upgrade problem.
Complexity of the Upgrade Problem
- given any request for install/remove, there are an exponential number of solutions (NP-complete)
- there could actually be this many, and how do we choose the best?
Package metadata is used to figure out solutions, including:
- name
- version
- conflicts: “Don’t install this alongside!”
- features: “What is provided by installing this?”
Properties of a repository of components:
- abundance: every package in the repository has dependencies satsfied by other packages in the repository (like a little, closed ecosystem that doesn’t need anything external)
- peace: no package in the repository conflicts with another package in the repository.
The authors then present theorums (and proofs!) for the following (these are again verbatim):
Theorem 1.
Satisfiability of package upgrade requests is NP-complete, provided the com-ponent model features conflicts and disjunctive dependencies.
Theorem 2.
Installability of a package in an empty environment is in PTIME in any of the two following cases:
- The component model does not allow for conflicts.
- The component model does not allow for disjunctive dependencies or features, and the repository does not contain multiple versions of packages.
Complexity in the Case of Component Evolution
Installing new packages gets more complicated in that you have to upgrade old packages. Different managers handle this differently:
- Debian only allows installing one version of a package at a time
- RPM allows installing multiple at once, but it won’t work if packages with the same version have the same filesyste path
flat means that two packages can’t be installed with the same name.
Theorem 3.
Existence of a flat installation containing a component is NP-complete, even when the component model does not allow for explicit conflicts, alternatives, and features.
Dealing with exponentially many solutions
This is the step where we evaluate solutions as “paranoid” or “trendy” or otherwise try to satisfy user preferences.
Dependency solving as a separate concern
The upgrade problem needs to be represented in a structured way in order to be able to “treat dependency solving as a separate concern.” We need to know:
- describe all known installed and available components
- describe components that need to be installed, removed, upgraded with constraints
- what the user wants (user preferences)
They again present CUDF, a domain specific language to represent points 1 and 2. CUDF has:
- platform independence: agnostic to package manager, version scheme, etc.
- solver independence
- readability: it’s a simple text file
- extensibility: only essential properties are captured in CUDF, but you can declare and use others
- formal semantics: e.g., the structured terminology
Their CUDF section here is exactly the same as in [1], I guess it’s okay to plagarize yourself :)
Mancoosi International Solver Competition
The authors discuss specifics of MISC 2010, generally, participant solvers received a CUDF document as input and needed to produce a CUDF encoded solution. There were problems ranging from easy to difficult, and participants could choose a paranoid or trendy scenario.

And there are complete results of the competition on page 17:
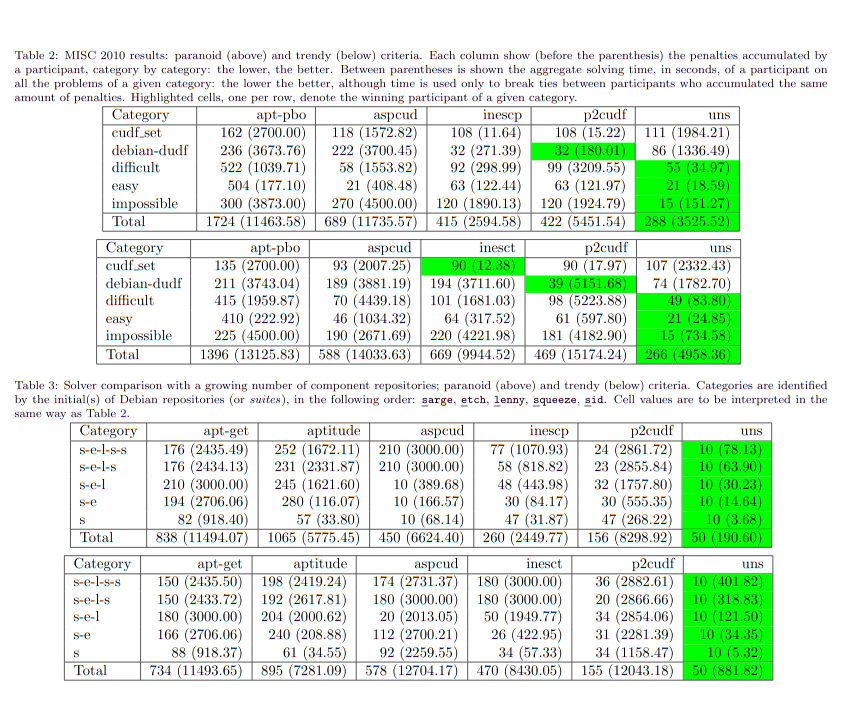
It’s interesting that the solvers perform differently depending on the problem sets. The “trendy” scenario is always more complex because there are more parameters. Figure 6. has a chart that compares package managers, but it uses patterns for bars and is incredibly hard to read. It looks like unsa is the best, consistently finding the best solution and being fastest.
Data and Appendix
- Appendix A and B have nice summaries of CUDF
- P. Abate, R. Di Cosmo, R. Treinen, and S. Zacchiroli, http://www.sciencedirect.com/science/article/pii/S0950584912001851“A modular package manager architecture”</a> Information and Software Technology, vol. 55, no. 2, pp. 459–474, 2013. Full details | PDF
- P. Abate, R. Di Cosmo, R. Treinen, and S. Zacchiroli, “Dependency solving: a separate concern in component evolution management,” Journal of Systems and Software, vol. 85, no. 10, pp. 2228–2240, 2012. Full details | PDF